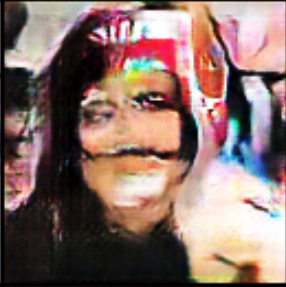Ganfluencer: Generating Beauty Influencers using GANs

Table of Contents
Introduction #
Despite infrequently wearing makeup, I have a passing interest in ‘beauty influencer’ culture on Instagram and YouTube. And everyone knows that when you’re interested in an area, the first thing to do is to help an AI learn something from it. Even if that “something” is how to apply good foundation.
The main motivation behind this project was to see if I could emulate the visual style of content creators in the beauty sphere. They seem to follow a set of unspoken ‘rules’ when creating media e.g YouTube thumbnails, Instagram stories etc, and people looking ‘grow’ often follow suite. This creates a distribution of images that lends itself well to being modelled by a generative adversarial network (GAN).
Code for the entire project is available in the GitHub repo.
Data Collection #
I had a few ideas about the data source to use to generate my beauty influencers (BI), but I decided on thumbnails due to their accessibility via the YouTube API. Another option was to try downloading similar content from Instagram, which I might try in the future.
To download the data off YouTube I originally tried using Oauth2.0, however the verification was an issue due to the number of calls I was making. This slowed down the download process considerably. Next I tried generating a refresh token, which I hear is a completely legit way to bombard YouTube with requests. After that failed, I finally discovered the youtube-data-api Python package and breathed a sigh of relief.
In terms of data selection I went for the top 50 results (the maximum returned from a request) of a whole bunch of BI related search terms. Don’t ask me how I have accumulated this infinite wisdom.
search_terms = ['makeup', 'grwm', 'GRWM',
'makeup haul',
'first impressions', 'beauty', 'kbeauty',
'instabaddie', 'makeup tutorial', 'everyday makeup',
'best makeup of 2019', 'the power of makeup',
...
]
At the time of writing I had 59 terms, giving a total of 2950 thumbnails and snippets. Each snippet also contained metadata about the video, such as the title, channel name, date etc. In the future, it would be cool to use this data and GPT-2 to generate new video titles. Here is an example of a returned API request.
{
"kind": "youtube#searchResult",
"etag": "\"OOFf3Zw2jDbxxHsjJ3l8u1U8dz4/FyYVdN5SIlx0_lI1UsyU3ECzLMI\"",
"id": {"kind": "youtube#video", "videoId": "eimxHdVfp1g"},
"snippet": {"publishedAt": "2019-12-03T16:36:02.000Z", "channelId": "UCxhWYXkLE8mOutRK55-WoSA", "title": "24hr Glow Up",
"description": "Watch me improve my appearance for no reason at all other then boredom, enjoy! Also apologies for the glitches no idea what happened there\ud83e\udd23 Here are all my ...",
"thumbnails": {"default": {"url": "https://i.ytimg.com/vi/eimxHdVfp1g/default.jpg", "width": 120, "height": 90}, "medium": {"url": "https://i.ytimg.com/vi/eimxHdVfp1g/mqdefault.jpg", "width": 320, "height": 180},
"high": {"url": "https://i.ytimg.com/vi/eimxHdVfp1g/hqdefault.jpg", "width": 480, "height": 360}},
"channelTitle": "Ryley Isaac", "liveBroadcastContent": "none"}
}
There are a few different resolutions available under the thumbnails key, but I found the medium size to be the best trade off between detail and file size. The size of each medium thumbnail is 320 × 180.
Because the data I have is unpaired and unlabelled, I used the classic DCGAN as a first pass. The code for my project is available in the GitHub repo. For training on my PC, I have a NVIDIA RTX 2070 which helped immensely for local development.
The data is quite messy, although obviously this is going to be the case for any real-world dataset. Some of the main inconsistencies for me are close ups of the face e.g eyes, ‘hack’ videos such as a sieve video (???) and adverts. As I discuss later, filtering the images will be one of the next steps in the project as the dataset grows.
Results #
DCGAN with 200 epochs #
First, I ran DCGAN with 200 epochs. This took around 10 minutes on my GPU. Here is the output grid for the final iteration.

After completing initial rounds of training, I wasn’t too happy with the output, although it was very quick to train. The general ‘concept’ was forming through the colours and shape, but the main issue was the resolution and image size. 64 x 64 was proving difficult to discern finer detail, or perhaps the network wasn’t picking up on certain features yet. The output seemed fairly stable despite the small sample size which was promising.

Big-DCGAN with 200 epochs #
I knew what I wanted next, and it was more resolution. I modified the original DCGAN network to output 128 x 128 images by adding another convolutional layer and increasing the upsampling of the images.
This increased training time substantially. 200 epochs took around 4 hours on my GPU. You can find this model in ganfluencer/bigdcgan here.
Here is an animation of the output images from 0-200 epochs, with 25 images per mini batch.

Big-DCGAN with 1000 epochs #
<= 500 epochs #
In my opinion, the most visually pleasing results were found around this point, before the gradient went ‘out of control’. Interestingly I found that the model had picked up on salient features of the thumbnails, e.g the high contrast white text, ‘before and after’ style split with a face on either side and psychedelic color palette.

Here are some individual examples of output from this stage in training.






>500 epochs #
However after this point, it can be seen that the network starts to overfit to the training data and becomes really unstable, mainly due to the relatively small sample of <3k images (some of which are duplicates).

As the network sees the same examples multiple times, it falls into local minima from which it can’t escape. This is a problem with GANs called mode collapse, where the generator starts producing identical samples aka a handful of ‘modes’.
This can be seen particularly in the final epoch.

And of course, this conclusion is supported after we look at the losses.
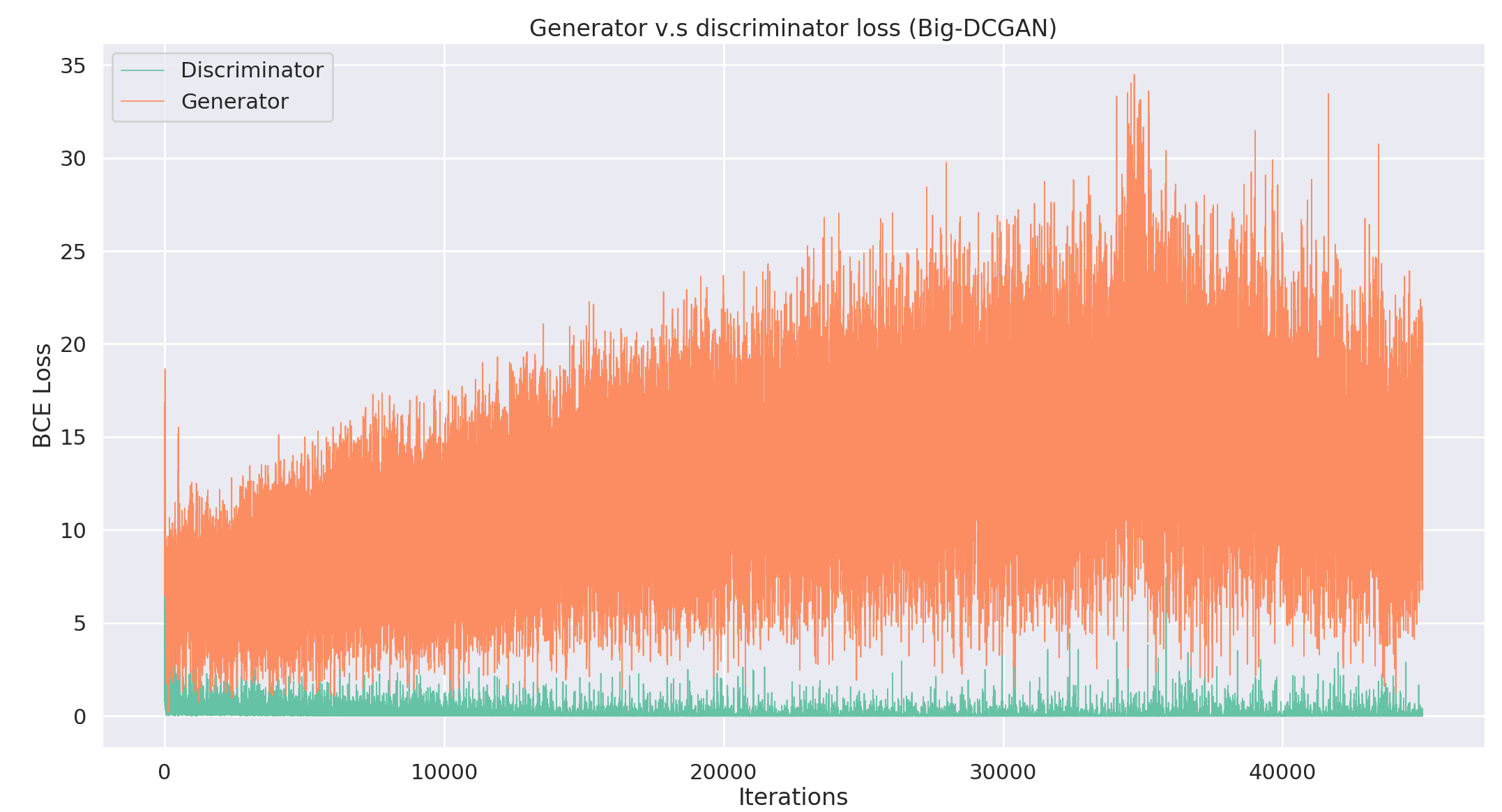
The main issue here is stability. Each iteration/epoch brings about massive shifts in the loss, which is then reflected in the images. It is clear that we would not reach a state of convergence letting training continue.
Next Steps #
I’d like to make a new post getting my hands on a RTX 3080 collecting some more data, cleaning the dataset more thoroughly and doing more hyperparameter tuning.
Other next steps I want to implement are:
Face region cropping: After some deliberation I think the centre cropping is preferable for preserving the ‘structure’ in the thumbnails. For example, a lot of thumbnails feature the same person on both sides e.g in the ‘before and after’ category. However it would be interesting to see if ‘thumbnail faces’ can be used for face generation, also given the fact you can export to higher resolutions.
Progressively growing GAN: These have enjoyed research interest due to their stability during training (see ‘Progressive Growing of GANs for Improved Quality, Stability, and Variation’); I would like to implement my own version in PyTorch and see what the improvements are to the images and loss.
Removing duplicate images: Because of the high amount of overlap in search terms, the same video may appear in the top 50 results for multiple searches. Some filtering should be done to avoid biasing the network towards these images.
More data! I stopped downloading data when I hit around 3000 images to start experimenting. Because content is constantly being uploaded to YouTube, especially in the beauty sphere, it would be great to expand the training set and capture more variation. This is relatively easy to do, just keep running the data collector every week or so, discard duplicates and train using the new batch.
Conclusion #
The stability of GANs for image generation is a tricky but visually exciting problem. Trying to generate complex ‘natural’ (well, natural for YouTube) images from a small dataset was a challenging task, and I think that this post demonstrated some of the key issues faced when training GANs (e.g mode collapse, non-convergence).
Sadly, I probably wouldn’t take makeup tips from any of the generated influencers.
Extra Images #
Just for fun ✨ (click on the arrows to scroll)