This lemon does not exist

Table of Contents

These lemons aren’t real 👻
Okay so hear me out. The bane of machine learning is data, clean data to be precise. Hard to come by, expensive to buy, and when you eventually get it you usually you spend most of the time on your project cleaning/resizing/cropping/throwing pens at your monitor from the sheer hellishness of the choices that were made by whoever put together your dataset.
So you can imagine my pure unadulterated, childlike joy when I discovered the lemon dataset by Software Mill.
The Low Down #
Lemon dataset has been prepared to investigate the possibilities to tackle the issue of fruit quality control. It contains 2690 annotated images (1056 x 1056 pixels). Raw lemon images have been captured using the procedure described in the following blogpost and manually annotated using CVAT.
From github.com/softwaremill/lemon-dataset
And let me tell you, I have yet to come across a more pure creation. All of the images are the same size. The segmentation labels are organised into a csv with a sensible format. The objects in the images are centered, square, HD and have a normalised background. What more could you ask for? I’ll stop raving soon I promise.

Crop of the lemon-dataset cover image. From github.com/softwaremill/lemon-dataset
So what to do with this beautiful dataset? Generate fake lemons, of course.
Synthesising lemons #
To do this dataset justice, I knew I had to use a state-of-the-art (SotA) network. As NVIDIA has recently released StyleGAN-2 with Adaptive Domain Augmentation, I decided to use this. I won’t describe the network here (maybe in another post), but here’s the paper and GitHub.
Now my MSI RTX 2070 GPU only has a measly 8GB of memory, which means I won’t be able to run this network at 1024x1024 or even 512x512 without paying for cloud compute. This network is big. So for now, I generated 256x256 lemons.
Training the network #
Getting StyleGAN up and running with my citrusy dataset was straightforward. I first added 2 lines to the dataset_tool.py file to resize my images to 256x256 when converting to TFrecords (as I am lazy).
img = cv2.resize(np.moveaxis(img, 0, -1), dsize=(256, 256), interpolation=cv2.INTER_LANCZOS4)
img = np.moveaxis(img, -1, 0)
I then ran:
python3 dataset_tool.py create_from_images ~/stylegan_datasets/lemon-dataset ~/datasets/lemon-dataset/lemon-dataset/images
Which gives you a folder of StyleGAN ready TFrecords.
To kick off training, I used:
python train.py --outdir=~/training-runs --gpus=1 --data=~/stylegan_datasets/lemon-dataset --resume=ffhq256 --snap=10
This will perform transfer learning from a larger dataset using a pretrained model from NVIDIA. Transfer learning is great for small datasets like this (2960 images) as the network has already learned the low level features like edges and contrast. Therefore when we train on our (comparatively) little GPU we don’t need to waste computation doing it again. I could probably spend a lot of time here tweaking the hyperparameters, however training is so slow on my machine that I just used the defaults. Let me know if you get better results with different parameters if you have a go yourself!
Results #
When the init images were printed, I’ll admit I was mildly terrified. The neon colour palettes are from the augmentation used by ADA, and the faces are from the FFHQ dataset. I was expecting lemons, not horror film outtakes. 👻

However when the next round of images were printed, I was already impressed. The network quickly learned the features of the lemons (small dataset combined with the clean pre-processing done by softwaremill). So as it progressed to the later epochs, it even started to pick up features like mould. Gross, but awesome.
To generate fake lemons, you then use this command, specifying the network .pkl that you want to load. The seed range is the number of unique images to generate.
python generate.py --outdir=out --trunc=1 --seeds=0-100 --network=~/training-runs/00006-custom-mirror-auto1-resumecustom/network-snapshot-000604.pkl
Here are a few lemon hallucinations. Training was for 192 ticks total with 1 GPU and took around 13 hours.
Healthy lemons #









Mouldy lemons #






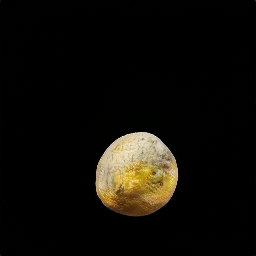





Overall I’m very happy with the results. It seems like StyleGAN-2 with ADA can learn high resolution details and get an surprising amount of variation on a very small dataset. And something new I learned - transfer learning is possible with GANs!
GAN out-takes #
In these images, the GAN failed to generate a realistic background and there are some visual artifacts.
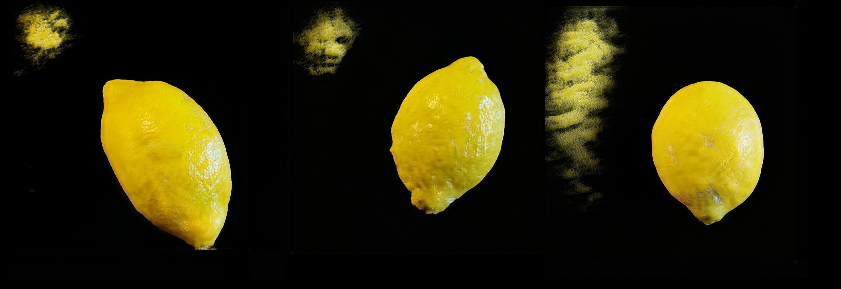
Applications #
You may be thinking, okay great. You have a way of generating infinite pictures of lemons. Thank you for your contribution to humanity.
What I say in response to this, is that this network could be incredibly useful for speeding up the quality control process. If you look at the steps carried out to produce the images themselves in the blog post, you’ll see it was pretty manual and time-intensive.
After carefully checking the package and verifying whether the classification is correct we started designing our DIY photo station. We knew that time is short and to avoid the risk of lemons rotting before capturing a photo in the relevant category we had to be ready as soon as possible with our setup. Another example from the blog post why it was a challenging process
By using a GAN to generate fake lemons, the time spent on photographing them, setting up the photo suite etc could instead be spent manually annotating the images, improving the verification process or trying out new segmentation/generator networks. Or, spending the freed resources on compute to train a higher resolution GAN.
Conclusion #
Finally, kudos to Maciej Adamiak for making this dataset. I saw they have a post about dataset augmentation using text-to-image GANs too (which I saw after writing this post, great minds think alike?) so check that out. I’d recommend having a play around with this dataset yourself and seeing what new applications you can think of. Let me know what you create!